

In addition to clinical biologists (and probably their assistants), every development-research enthusiast nowadays is fairly familiar with the term ‘Randomized Control Trials’ or RCTs, as they are fondly known. Since their inception in the early 2000s, RCTs have influenced research in development economics, and consequently, careers of several aspiring economists or ‘randomistas’ (Ravallion, 2009). Fast forward 17 years and today we ask ourselves the question ‘are RCTs the only way to measure and evaluate impact?’ or ‘are RCTs subject to availability bias?’. Although still regarded as the ‘Gold Standard’ in impact evaluations, the sheen on RCTs is slowly fading away, due to the high costs associated with them. Though RCTs help in answering what works, the question of why it works is left open. Newer and improvised methodologies are catching up with the trend to fill in these gaps.

Field experiments done in the past have helped policymakers answer certain essential questions, such as the effects of distributing deworming pills or the impact of distributing free textbooks in schools. However, a major source of concern is that RCTs, by virtue of their design, tend to have high temporal as well as monetary costs. On an average, it takes half a million dollars (Han, 2016) to conduct a social experiment in the field. To put things into perspective, at least USD 965 million has been spent on RCT-based studies[1] in the past 15 years. In terms of the life-cycle of an RCT-based evaluation the journey from esoteric economic journals to pragmatic policy implementation can take an average of 4.17 years (Han, 2016), with some flagship projects extending up to 10 years. This often results in a policy lag where the economic, social and political factors might have changed, raising concerns about the internal validity of these studies which is of first-order priority.
In certain cases, even if the transformation process from theoretical evidence to policymaking has been fast-paced, there are newer bottlenecks in the implementation process which the study may not have originally addressed. For example, Han quotes a study conducted in 2012 in Kenya that showed the effectiveness of short-term contract teachers in increasing test scores. However, the reality on-the-ground showed that the scale up was successful in a specific context i.e. only when a non-profit partner implemented the programme, rather than the Government.
Thus, research design as well as implementation of RCTS bear equal relevance in determining the causal attributions. Angus Deaton rightly summarised this by stating that RCTs typically answer the question of ‘what works’ rather than why it works (Angus Deaton, 2016). Understanding the mechanisms of change, which is of paramount importance in policymaking, requires supplementing RCTs with other refined methods that can shed light on the causal pathway.
The Era of Optimization
In the light of the perceived limitations of RCTs, the time is now ripe to seek innovations that make RCTs more efficient and effective. This is particularly important for a country such as India, which finds itself in a ‘missing middle’ situation with respect to international development aid. With 252 studies, India also ranks first in the number of impact evaluation studies conducted between 1981 and 2012 (Drew B. Cameron, 2016). This points to an evident case of saturation with respect to development aid. The financial and time crunch in the current scenario indicates the need for optimized methods that can support Governments and policymakers in taking evidence-based decisions, with no comprise on rigor.
Figure 1 Heat Map of low- and middle-income country Impact Evaluations (1981-2012)
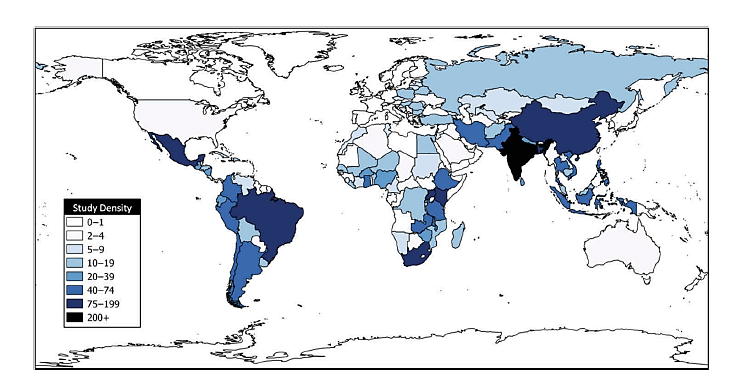 Source: Cameron et. al (2016), Journal of Development Effectiveness
Source: Cameron et. al (2016), Journal of Development Effectiveness
Enter Rapid Fire Tests
Rapid prototype testing (A/B testing/Rapid Fire Tests) refers to the process of evaluating program designs and improvising them, based on the impact they create. An evolved cousin of RCTs, A/B tests use behavioral insights to understand the reasons behind why a program may or may not work. For example, using different versions of SMS reminders to remind people about their savings commitments. Tracking such interventions over a period of time to understand the overall welfare impacts would qualify as RCTs, whereas rapid fire tests involve using secondary data sources to test achievement of specific targets and incorporate changes to devise an intervention which is a better fit for the research and policy question at hand.
The use of A/B tests in driving social change has been pioneered by ideas42 and IPA in countries such as Philippines, Peru, Uganda, Bolivia, Pakistan and Sri Lanka. The focus thus far has been on issues such as increasing adoption and usage of financial services among the unbanked poor and better debt management among low-income populations.
In the developed world, the Governments of the United Kingdom and USA have acknowledged the potential of integrating behavioral insights to program delivery. As a result, a quasi-governmental entity – the Behavioural Insights Team was set up by the UK Government, and the White House set up the SBST – Social and Behavioural Sciences Team.
In addition to this, one of the most credible validations to use the A/B testing methodology comes from IPA and Centre for Effective Global Action (CEGA). Their Goldilocks initiative highlights best practices that social entrepreneurs and non-profits can follow in monitoring and evaluation (M&E). The toolkit of methodologies includes A/B testing as an effective way of evaluation (IPA, 2016).
Two Sides of the Same Coin
The main advantage that A/B tests offer over RCTs is that these tests are deeply intertwined with implementation, unlike traditional RCTs. By relying heavily on easily scalable interventions, A/B tests are pliant and help minimize costs of evaluation as well as streamline scale-ups.
By focusing on administrative data collected, the feedback mechanisms under these tests are much quicker, and thus enable researchers to test several hypotheses within the given time and resource constraints. Further, primary data collected from administering household surveys runs the risk of using self-reported data in formulating policies. Using real-world data also has the advantage that the outcomes are relevant to the decision-making processes, which bear long-term policy implications due to high external validity (G & P, 2014). The following table provides a snapshot of the differences between RCTs and A/B tests.
Table 1: A Snapshot of Key Differences between RCTs and A/B Tests
|
Characteristics |
A/B tests |
RCTs |
|
Intervention |
Low-cost modifications to existing product/ scheme |
A new product/ scheme or a modification to existing product/ scheme |
|
Data Sources |
Administrative data (usually collected from secondary sources such as transaction history, call logs, telemetry data etc.) |
Administrative data and survey data collected from primary sources. |
|
Outcomes |
Focus on first-order proximate outcomes such as take up, enrolment, usage, attendance, etc. |
Focus on welfare outcomes such as income, consumption, wealth and so on. |
Source: IPA Blog (Dibner-Dunlap & Rathore, 2016)
In 2015, IDinsight proposed a separation between ‘Knowledge-Focused Evaluations’ (KFEs) and ‘Decision-Focused Evaluations’ (DFEs (Shah, Wang, Fraker, & Gastfriend, 2015). Whereas KFEs primarily aim to contribute to knowledge regarding development theory, DFEs are tailored methods that set sights on context-specific decision-making. In line with this, while RCTs are placed within the realm of KFEs, A/B tests which are intensive methods used for applied decision-making can be categorized as DFEs.
In India, IFMR LEAD has kicked off two studies using the methodology with capacity-building from ideas42, to test technology-based interventions. These studies include – a study focusing on increasing digital payment uptake and usage among small scale merchants; and another working towards improving private wealth management practices of Uber drivers. Such studies fall in the latter category of DFEs and hold the potential for being scaled up effectively.
To make RCT studies more effective, Sendhil Mullainathan, a proponent of cognitive economics suggests integrating ‘mechanism experiments’ into policy evaluations (Mullainathan, Ludwig, & Kling, 2011). Similarly, Maya Shankar, Senior Policy Advisor at SBST in the White House, stresses the importance of using behavioural understanding to define fundamental features of a policy or program to make it more effective (Dubner, 2016).
Secret Recipe for a Successful Evaluation
In the fight against poverty, researchers in the field of development economics have achieved a lot in the past decade. The emphasis on data and rigor for policymaking is praise-worthy. However, to inform development action more effectively, it is necessary to integrate several methodologies that can account for robust evidence in evaluation. Conducting either several short-term A/B tests or encompassing them into a large scale RCT can be a force multiplier. The choice of the methodology, however, should depend on the constraints as well as the potential to scale up the policy and sustain it in the long term.
References
Angus Deaton, N. C. (2016). Understanding and Misunderstanding Randomized Controlled Trials. NBER Working Paper No. 22595.
Dibner-Dunlap, A., & Rathore, Y. (2016, August 1). Beyond RCTs: How Rapid-Fire Testing Can Build Better Financial Products. Retrieved from IPA Blog: http://www.poverty-action.org/blog/beyond-rcts-how-rapid-fire-testing-can-build-better-financial-products
Drew B. Cameron, A. M. (2016). The growth of impact evaluation for international development: how much have we learned? Journal of Development Effectiveness.
Dubner, S. (2016, November 2). Freakonomics Radio. Retrieved from Freakonomics: http://freakonomics.com/podcast/white-house-gets-nudge-business/
G, P., & P, M. (2014). Market Access and Reimbursement: The Increasing Role of Real-World Evidence. London: Parexal International.
Han, C. (2016, November 14). Trials and Tribulations: Relevance Beyond the Poverty Lab. Kennedy School Review.
ideas42. (2017, March 6). Nudge to Action: Behavioural Science for Sustainability. Retrieved from ideas42 Blog: http://www.ideas42.org/blog/nudge-action-behavioural-science-sustainability/
IPA. (2016, March). Goldilocks Toolkit. Retrieved from Innovations for Poverty Action: http://www.poverty-action.org/goldilocks/toolkit
Mullainathan, S., Ludwig, J., & Kling, J. (2011). Mechanism Experiments and Policy Evaluations. NBER Working Paper Series.
Ravallion, M. (2009, February). Should the Randomistas Rule? Economists’ Voice, pp. 1-5.
Shah, N. B., Wang, P., Fraker, A., & Gastfriend, D. (2015). Evaluations with impact: Decision-focused impact evaluation as a practical policymaking tool. New Delhi: International Initiative for Impact Evaluation Working Paper 25.
[1]According to 3ie’s Impact Evaluation Repository, 1930 impact evaluations have been done using the RCT methodology. Taking $0.5 million as the average cost of one study, the total average stands at $965 million.



